AI factory — Parties 2&3 [EN]

06/10/2021 par Marie-Fleur Sacreste
How we industrialized deep learning algorithms to production by building a unique agile framework. This series explains how we create super performing models even on premise.
As I explained in Part 1 of this series, most data scientists and communications around AI focus on performances and how to get the best F1 score or mAp. However when developing AI enabled systems (especially on premise like Preligens) performances are key but they are only the tip of the iceberg.
The hardest technical challenge to overcome is to take this performance to production, to iterate fast enough to improve the product with an industrial approach.
Growing from 1 to a 70 people tech team, all working on deep learning and artificial intelligence, in less than 4 years — our first employee arrived in July 2017! — we faced production problems daily.
How to scale teams and technology fast enough ?
How to scale and still improve algorithms and ensure they are reproducible, maintainable and standardized for the whole company and products ?
In this article we will explain how we managed to industrialize the creation of new detectors and made the integration of state of the art models easy to use and deploy even when products are deployed on premise, sometimes even on classified environments.
Our strategy :
- Focus on research and development : A dedicated R&D team to test and integrate state of the art research into our models, in test but also in production
- Create a unique framework : our AI factory : A toolbox for our AI teams, helping them create in a short period of time high accuracy and reliable detectors, to industrialize AI algorithms creation.
- Dedicate a team to this framework : our AI engineering team. A third of our AI engineers are working on the framework. This is a multidisciplinary team, from Machine Learning engineers, to computer vision researchers, architects, fullstack developers and devOps.
Our AI factory makes it possible to :
Part 1 — Scale our company ensuring quality and reproducibility of our detectors: More than a dozen people are working on the framework full time with an expected growth of 60% in 2021.
Part 2 — Create the best possible performing models : Never less than 95% and up to 98% accuracy with State of the Art model architecture.
Part 3 — Shorten the cycle between research and production: With our AI factory, once an innovation has demonstrated its potential, it takes less than 3 months to go from our research team to the client premise.
This article explains Part 2 and 3 of our AI Factory.
Create super performing models
Prediction
Training a model is one thing, but to check it’s performing well is another. With our AI factory we wanted to go further. We developed a whole toolbox with pre-processing, post processing, model ensembling, and many evaluation metrics providing our team with the best tasks to improve models. Experienced data-scientists can then select and orchestrate the relevant tasks for their model using once again a simple yaml file. Our AI factory will take care of the rest. This is really a game changer for our teams that have a reliable, easy to use and performing tasks orchestrator.
Pre-processing makes sure images will be compatible with our models (band composition, orthorectification, 16 bits to 8 bits conversion…).
We have today more than 20 post processing (size filter, make line straights, clean, merge and filter vectors …). All teams can contribute in this like-an-open-source framework. To ensure quality, since this is the part deployed at our client’s, we test, review new proposals and share good coding practice.
Integrating State of the art R&D
In order to succeed in the longer term, a scale up company has to stay on top of R&D and integrate State of the art research.
But it is one thing to test within your R&D team, it is another to make it available to be integrated into the products delivered to the client in production.
Once again our AI factory makes this dream come true.
State of the art bricks are available to be integrated in the pre-coded architectures: skip connections, squeeze and excitation, or attention modules for instance. This architecture allows us to use papers on innovative architectures easily which could take months without it.
For instance, our AI factory helps us use active learning. Thanks to Valohai and our AI factory, teams can easily pick up the right tile to feed back our model, keeping the same high results but with 6 times less amount of tagged data !
Saving time and focus on problem solving
At Preligens, we want to let Data scientists focus on where their impact will be the highest: the choice and selection of the right training and testing sets, the right architecture and right training settings. We have simplified the process of creating algorithms so that they spend more time on things that matter:
- choosing the right data according to the use case
- reaching the top % of accuracy to deliver the best quality products
Pre-coded algorithms
As you’ve seen in the last chapter, our framework is a game changer since data scientists don’t have to develop a model each time, test it and improve it.
This framework not only ensures reliability and performance, it’s also a time saver for them. No need to focus on the code and its tests : teams can concentrate on finding the best architectures within the 20 we have in our library and focus on finding the best configuration. And if a new architecture can be impactful for our use case, our framework makes its integration and use super smooth.
For MLOps part of our job, we use Valohai that makes it incredibly easy.
Launched by CLI
Because manual steps increase the time to prod and the risk of human error, we have created command lines to automate all possible steps of algorithm creation.
Now, with one command, one can create a training and testing dataset, launch a training, a prediction, select a specific branch for a training, create a docker image of our model to prepare its deployment and so on.
To go further into the prediction, one can also easily launch a RPS (running point search) to get different predictions by changing some parameters, add a geofence pattern or also select a specific machine for its prediction.
Dashboards to simplify data selection
AI only works if the machine can ingest and test enough data. Having millions of observations is one thing, but selecting the right ones to train and test our algorithms is another. Data is the power of our model and we need to make sure we get a balanced training and testing set. Together with state of the art models, we can reach high performance with our client data.
To do so, our AI factory provides a dashboard, Kibana, used to select observables, contexts (% of snow, vegetalization, fog…), desired level of classification (with up to 4 levels for some observables) within a blink of an eye.
Thanks to the Kibana request, our framework, a yaml configuration file and our CLI (command line interface), teams can build a dataset in less than 5 commands.
Visualization tools for decision making
Helping teams to decide if one model/configuration is better than another is the last mission of our AI factory. To do so, we use Valohai, our MLOps platform.
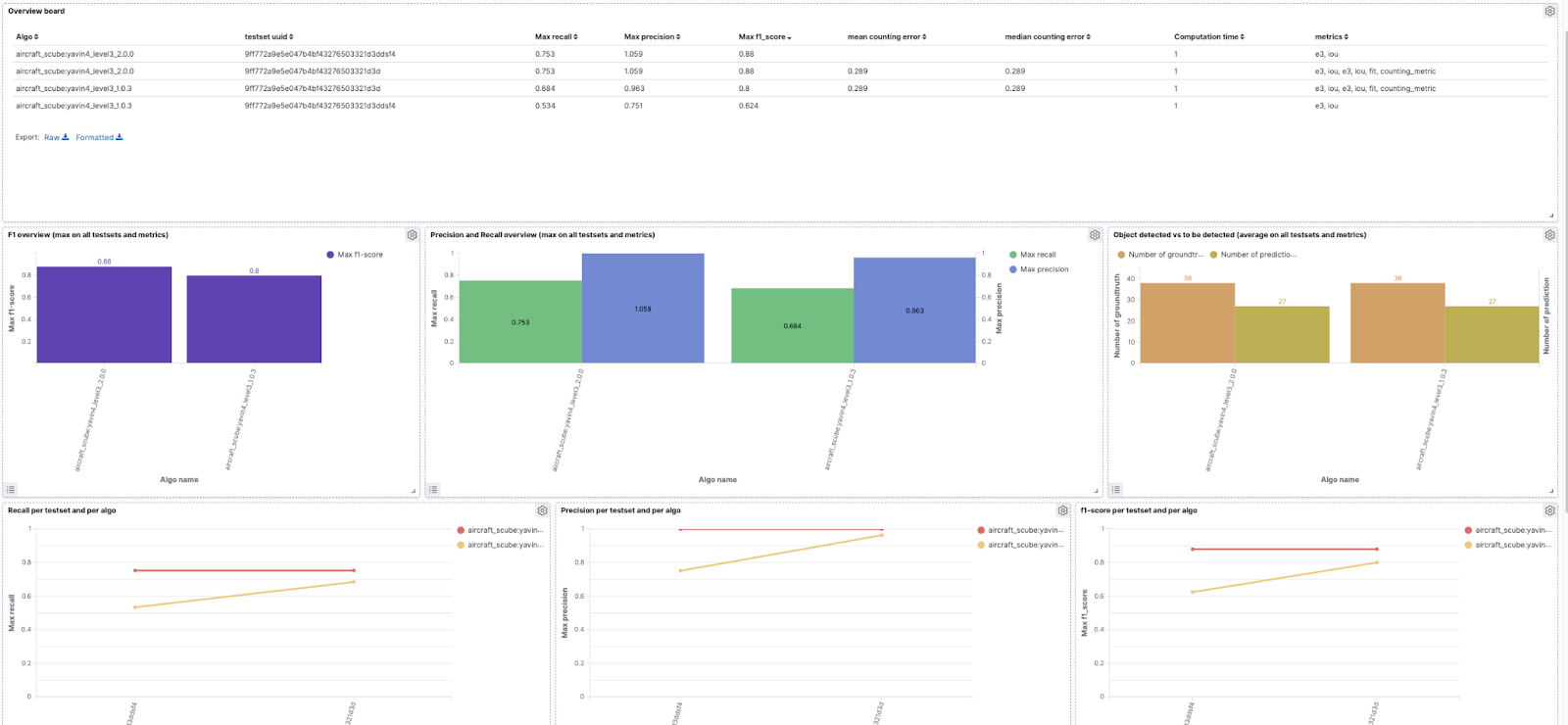
But we also created our own dashboard to visualize images and algorithm detection and all main metrics to pick up the right version to deploy. These new dashboards have just been deployed and we are actively working with the teams to provide new ones. Our goal is to continue improving their day to day work.
Conclusion
Our AI factory is a unique agile framework we created to industrialize deep learning algorithms. It makes it possible for us to scale and build best-in-class products that are in production, on premise, even in very strict environments. It is exactly tailored to our needs while being very flexible and open. We can easily onboard newcomers, make our team save a tremendous amount of time and integrate state-of-the-art architecture to deliver cutting edge technology to our customers.
This article sounds like a tutorial to AI-companies who wish to scale and improve the product they deliver to their customers…
Feel free to let us know what you think !
Cover Image source: Manuel Nägeli/Unsplash
![AI factory — Partie 1 [EN]](/sites/default/files/2021-08/vignette-Medium.jpg)
![Utilisation de réseaux neuronaux profonds et d'images PlanetScope pour suivre la pêche illégale au thon en Méditerranée [EN]](/sites/default/files/2021-04/0%2Anzv_i4DqtsOIAPV9.jpg)
![Comment utiliser l'apprentissage profond sur l'imagerie satellitaire - Jouer avec la fonction de perte [EN]](/sites/default/files/2021-04/1_2.png)