Comment utiliser l'apprentissage profond sur l'imagerie satellitaire - Jouer avec la fonction de perte [EN]
02/26/2019, by Renaud ALLIOUX
Revealing the recipe for a product without giving out the secret ingredient can be challenging. Though at Earthcube, we believe in sharing tips and processes.
Introducing #TechSecret, an article series to dig deeper into the technical side of building our AI solution.
Loss — use cases relation
In machine learning, loss functions are computationally feasible functions which represent the cost of inaccuracy of the network, the “distance” between training images and the associated predictions. In other words, it is the function the whole training process is trying to minimize.
When training deep neural networks, the objective is to find the “best” minimum for the loss function. If this loss is well designed for the use case, these minima will get you the best performances and….
Wait a minute… You read that too?! “If the loss is well designed”?
What does it actually mean?
Loss functions are usually complex mathematical cost functions to be optimized in a multi-dimension space. It is usually chosen to be convex ( (imagine a giant multi-dimension bowl) when tackling simple machine learning problems (e.g. regression) but for deep learning applications, loss functions are usually neither even convex nor concave, making it even harder to understand its representation.
So, how is it possible to find the best combination of the choice and design of the function in order to fit your use case?
In this article, we will propose several examples of how cycling between losses and modifying loss functions can serve better performances and more relevance to a specific application.
The basics
A good loss has to have several qualities: first it should be mathematically light to compute, usually derivable (or the derivate should at least be estimated).
For segmentation, object detection or classification a common loss is cross-entropy:

It leverages the logarithm scale to be fast but accurate (large loss numbers have strong slopes, but small loss numbers are flatter, allowing larger learning rates) while being computationally simple.
However, it has some drawbacks:
The first one is that it is mathematically far from the metric that is usually evaluated for object detection.
Often, one would evaluate the IoU to evaluate the capacity of algorithms to detect objects on images. The usual threshold is 0.5, meaning that you need to detect more than 50% of an object for it to count as a good detection.
With cross entropy, you will get the same value if you optimize 50 pixels of one object as one pixel of 50 objects — which is not what you want in the end.
Moreover, cross-entropy does not take into consideration class imbalance.
If you take the example of car segmentation in satellite imagery, you will obtain the same loss improvement by getting a background pixel right as by getting a car pixel right, which can give misleading scores when 99% of pixels in your image are background.
Solving class imbalance
A simple way to solve the class imbalance issue is to introduce the notion of weighing in your loss. If you start by calculating the ratio of pixel/object between each class, you can then use this ratio to penalize more error on the less frequent classes. Again, a good example is the weighted cross entropy.
The formula is the same as the normal cross entropy, except that it is weighted for each class with a factor:
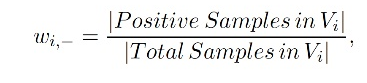
If we get back to the example of segmentation on an image composed of 99% background and 1% object, using weighted cross entropy, you will get 99 times more loss reduction by getting a car pixel right than by getting a background pixel right, thus maximizing the efficiency of your optimization.
Playing with this weight can also allow the data-scientists to go for more recall or more accuracy depending on the use case, but we will get back on that later on.
Using object-wise loss
In order to solve the problem of distance between loss and actual performance evaluation, a good solution is also to use object-wise loss, especially when dealing with segmentation.
Thanks to these, your neural network will optimize directly at the object level and the cross-validation metrics you will obtain will be much closer to the actual performances score. At Earthcube, we like to use Jaccard-distance loss to achieve this.
It is a direct implementation of the “intersection over union” formula: a great loss function to get clean, regular shapes in segmentation:
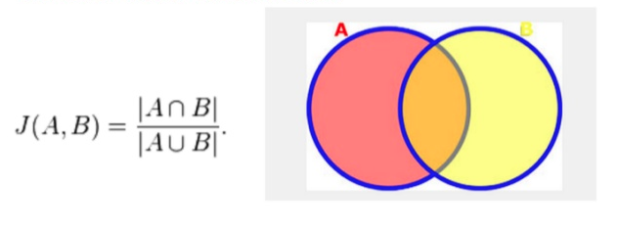
However, these losses, as all custom losses, are harder to manipulate than simple cross entropy. There are fewer tables that can diverge easily or strongly bias results towards precision.


Using loss as tunable hyper-parameter
This illustration is finally adaptable to all loss implementation: some are faster to implement, some are more stable and some can prevent class imbalance or score dependencies. A great example of that is the focal loss.
First implemented for retinanet (see here for details) the focal loss can be adapted to several applications and has lots of strong qualities: it copes with class imbalance and also introduces hard mining directly into the optimization process.
However, it can be highly unstable and it needs lots of fine-tuning to achieve good results on other architectures.

Moreover, by choosing the right loss and parameters, you can adapt and fine-tune your algorithm to your actual performance needs: as stated, Jaccard distance tends to bias toward accuracy while a strong weighted cross-entropy can be tuned to go toward recall.
Consequently, for small object detections, we have developed a process to take advantage of this.
We often start training with weighted cross entropy and then bias results toward recall to force algorithms to detect the necessary features.
When recall numbers are satisfying, we switch toward Jaccard-distance at a small learning rate to reduce false detection rates.
By cycling this process, we can improve performances and adapt the algorithm to specific use cases: if it implies counting objects, we will try to get balance performances while, if the use case implies detecting a needle in a haystack, we will use cross-entropy to bias results toward less false negatives, etc….
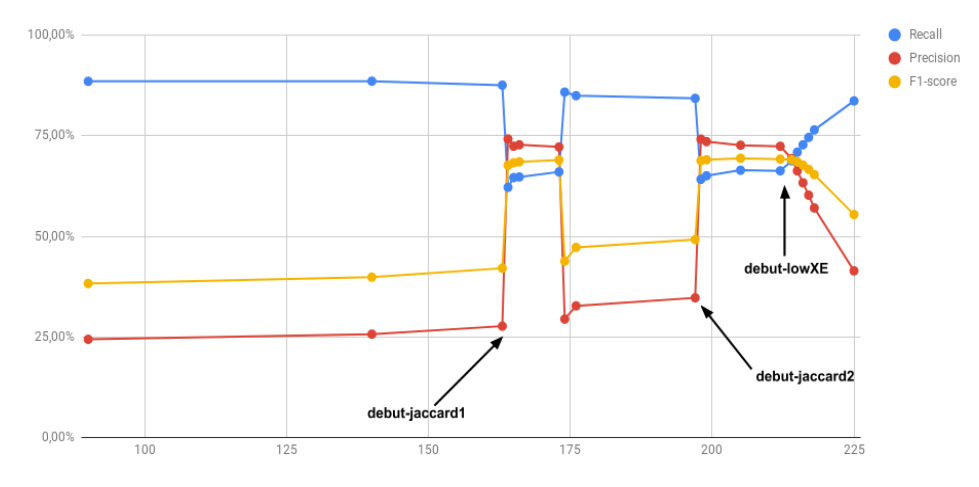
Mastering loss functions really is mandatory to get the most of your deep learning algorithms.
One needs to understand its theoretical basis as well as its applications and limitations to ensure that performances fit their clients’ needs.