How hard is it for an AI to detect ships on satellite images?

09/12/2020, by Renaud ALLIOUX
Asking for the moon during summer break
At Preligens, our job is mainly to monitor sensitive sites at a very large scale. We take dozens, potentially hundreds, of sites and use AI and satellite imagery to track strong and weak signals for security, defense, and financial markets.
We are able to detect vehicles, aircraft, ships, temporary constructions, infrastructures and various changes. We use semi-specialized detectors and post processing to reach the best performances and usually target above 90% F1 score on limited and controlled specific areas.
At the end of June, one of our clients asked for a generic ship detector on 30–80cm satellite imagery with very good performances (above 95% recall). It had to work on 8–16bit imagery, panchro or RGB, from any location in the world, without any specification on the sensor except resolution. Of course they needed it in less than 2 months and, to add to the difficulty, it was during the traditional “french summer break” when most (normal) people flee from Paris to more breathable areas.
Basically we had to solve ship detection on very high resolution satellite imagery in less than 50 working days.
From an external point of view, seeing Kaggle competition results or marketing announcements, it seemed simple. In the end, boats always have the same shape, the sea is always the sea… how complicated could it be?

We are able to detect vehicles, aircraft, ships, temporary constructions, infrastructures and various changes. We use semi-specialized detectors and post processing to reach the best performances and usually target above 90% F1 score on limited and controlled specific areas.
At the end of June, one of our clients asked for a generic ship detector on 30–80cm satellite imagery with very good performances (above 95% recall). It had to work on 8–16bit imagery, panchro or RGB, from any location in the world, without any specification on the sensor except resolution. Of course they needed it in less than 2 months and, to add to the difficulty, it was during the traditional “french summer break” when most (normal) people flee from Paris to more breathable areas.
Basically we had to solve ship detection on very high resolution satellite imagery in less than 50 working days.
From an external point of view, seeing Kaggle competition results or marketing announcements, it seemed simple. In the end, boats always have the same shape, the sea is always the sea… how complicated could it be?

A generic boat detector has to work on all of these (and more!).
Our approach
We were seeing several difficulties on this project.
- First, the timing was very short and we only had limited resources available
- Our database was only built for specialized detectors in segmentation and was not diverse enough for such a task
- Image diversity is close to infinite, so we had to emphasize on testing to ensure reliable performances
- Lots of studies are available but only few show good results and even fewer are tested on a database large enough to ensure that an industrial application is even possible.
Fortunately we have developed a very powerful framework to iterate fast and efficiently.
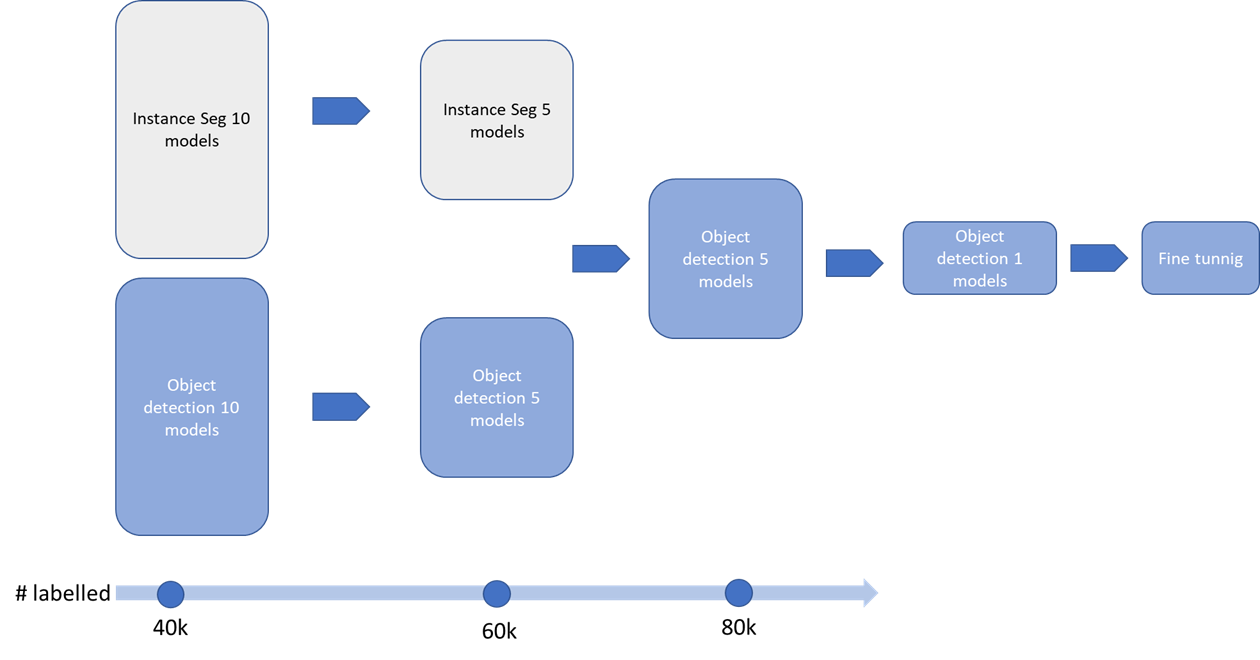
The first task was to separate training and labeling in three batches to iterate on different architectures as fast as we can and select best candidates.
We then tested both instance segmentation and object detection in parallel with ~20 different models, each model with several sets of hyper-parameters while increasing the database at the same time.
Labeling only what’s needed
The data labeling part was done using images from 30cm to 80cm on more than 15 different geographical areas. The production team worked closely with the data science team all along the project to deliver batches of new data corresponding to training iterations. We built a first dataset of 40k ships leveraging our already labeled database. We used it to train on the first 20 models. As ships are quite simple to identify on satellite imagery, we then leveraged our >500 000 km² VHR images database to visually test, at each iteration, dozens of full size images of harbors and shipyards. We used basic “Hard Example Mining” to grow iteratively the training dataset: we selected the images on which the detections were visually the worst and sent them for manual labeling. This is a simple but very efficient process to increase the performances of your model and reduce annotation and training times. Thanks to our labeling platform and outsourcing partners we now have close to 10k labels/day capabilities in segmentation (we label everything at pixel level for flexibility), so the process only took a few days.
We also kept several full size images of locations out of the training base to generate a testing set for final performances evaluation. This is really critical for earth observation imagery. You often see testing on the same geographic scene as the training, meaning often the same lighting, weather or landscape parameters (EO satellite are sun synchronous, so they always get above the same area at the same solar local time). If you want a generic detector, it has to work on scenes going from Canada to Australia, from 10am to 4pm, in winter and summer and even if the location is not in the training database.
Leveraging multi-resolution
We started testing proprietary instance segmentation and object detection models with numerous variations (number of layers, architectures etc…) and hyper parameters (loss, patch sizes, pre-post processing, optimizer). We generated automatic test reports after training on our test database with IoU >0.5 metric.
After two iterations, we only focused on object detection as instance segmentation was not significantly delivering better results and needed more resources.
After several trainings we ended up with a single model we tried to fine tune to meet the client’s need.
- >95% recall on ship bigger than 15m
- no real-time needed
- >85% F1 score
The problem was that on 30 to 80cm imagery, the ships’ size varies from 15 to 400m. Consequently, for larger ships on higher-resolution images, larger image patches are needed to preserve enough context. We tried to push entry patch size up to 2048px. However, at this size, we needed to reduce the batch size down to …1. Even on P100 GPUs, the benefits of using batch-norm layers was lost because of the inadequate batch size. A solution could be to down-sample images to lower resolution: At a resolution of 90cm, a patch of 1024 pixels contains far enough context to accommodate larger ship while allowing the use of batch normalization with reasonable sample sizes. Although with this technique, we ended up losing lots of recall on smaller vessels (<50m). At this point, we were stuck at around 80% F1 score and 90% recall, which was below requirements.
Our dataset already contained 30 to 80cm imagery, so using 1024 pixel wide patches at native resolution leveraged the benefits of batch norm without losing too much context, and we did not witness much performance gains by playing with up/down-sampling images during training. Nevertheless, this trick was used during inference: by taking a multi-resolution ensembling approach in prediction, we managed to get more context for large ships while retaining details for small ones. Our algorithm uses up to ten different resolutions (up or downsampled) for the same image to get a final prediction mask.

Final results are pretty satisfying. We pushed recall a lot due to the customer’s requirements so we had a few false alarms but this was easily solved using basic sea masking (false alarms were mainly on buildings or large trucks.)


Improvement could still be made using oriented bbox (see Yang et al 2018 here) and native multires training in order to reach better F1 score without sea masking, but these are complex developments. However we managed to pull out state-of-the-art boats detection in very agile cycle and very short timeline.
So, is AI that simple?
No, it is definitely not.
If you are not familiar with geographic data, accessing relevant images alone and setting up good labeling standard could take months. Developing a flexible training framework , standardized test practices and scalable infra require state of the art knowledge in machine learning, data engineering and software development. Even more importantly, there is no “magic trick” to solve every problem, but tools to be standardized for data-scientists to use. The same multires approach was tested in different observables and use cases and we ended up with even poorer results than the simple resolution approach.
To be honest most of large and small companies in this field still struggle to reach the maturity to be able to deploy and maintain industrial applications.
The key for us is to be able to test, on very short time-frames, dozens of different new models, hyperparameteres and tricks, with standard testing procedures and easy-to-use tools. With this approach our team can gain a lot of experience at a very high pace. However, it requires a very good machine learning framework, solid data and software infrastructures and very fast labeling capabilities.
AI is not simple, in fact it is a very hard field of work, especially when you are using remote sensing Data.
If you are interested in how infrastructures can unlock AI applications’ full potential, feel free to join our “AI in production” meetings in Paris.