AI products and remote sensing: yes, it is hard and yes, you need a good infra.

By the way, data scientists are also developers!
07/24/2018, by Renaud ALLIOUX
I have recently read several blog posts explaining how “data scientists are not developers”. Well, at least at Preligens, they are. Of course building an AI product does not require the same skills and IT knowledge as developing a web app, but this is true for every developer job. Embedded software development is not the same job as front end development for a mobile app, which itself is a different job from implementing a back end on AWS for an IOT company.
The common denominator of all these jobs is the fact that, in a startup, you are able to leverage the agility and speed of the team to iterate very fast on your developments and tests. And to do that correctly, you will need to implement tools, infra and automatic processes to ensure standardization, reproducibility and quality.
The need for agile cycles
What is common to data science products and other development jobs is this need and ability to iterate fast and to follow a cycle, regardless if you are training a new model or developing a new architecture. Of course, this cycle is specific to data science, as mobile app development has its own dev cycle.
This how we formalize it at Preligens:
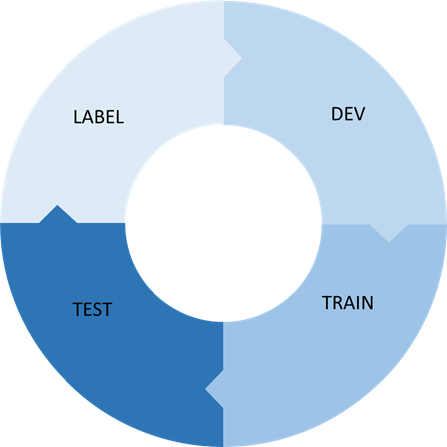
Each part needs to be backed by an infra and each integration has to be as automated as possible! This is also critical for the efficiency of your R&D.
A scalable and efficient infra can give you a significant technological heads up.
Back to the point
Building AI products based on satellite data is hard. It mainly comes from the scarcity, complexity and diversity of images, but also from the different problems that need solving.
Image labeling might be one of the most important steps of the cycle. As discussed in my previous post, satellite images are hard to deal with. They are heavy, expensive, do not include weak labeling and they need skills to be leveraged. Moreover, due to their nature, satellite images can involve confidentiality issues. They are also very variable in terms of resolution and quality, and the diversity of object of interest is tremendous. Hence, labeling must be done very carefully.
You will obviously want to have a clear knowledge of these assets at anytime: how many images you have, how many objects are labeled. It is also critical to be able to track the time needed for each labeling. Consequently, you will want this data to be ingested in your system as soon as possible in order to keep control over every parameter before and during labeling. You will also need a strong database to be able to reference this labeling and link it to the proper images. You do not want to get your data out of your system for labeling, whether you are using external or internal resources to do so. Eventually, you will need a strong quality control. Image interpretation is hard and requires skills and knowledge. While labeling millions of objects, you need to ensure that the quality remains as high as possible
This is why at Preligens we chose to build our own labeling platform, based on PostGis database, using GeoJson format and GIS standard. Designed and coded in less than 90 days, we are now able to perform labeling directly within our infrastructure, with no data coming out of our server at any time. Every action is tracked and logged and KPIs are generated live. Internally, we are able to access images and their related labels in real time, adjust the task if the quality decreases or even correct the process if instructions are unclear. This whole infra eases the pain a lot. Anytime, anywhere, I can connect to our data lake, track our progresses and anticipate data-related issues.
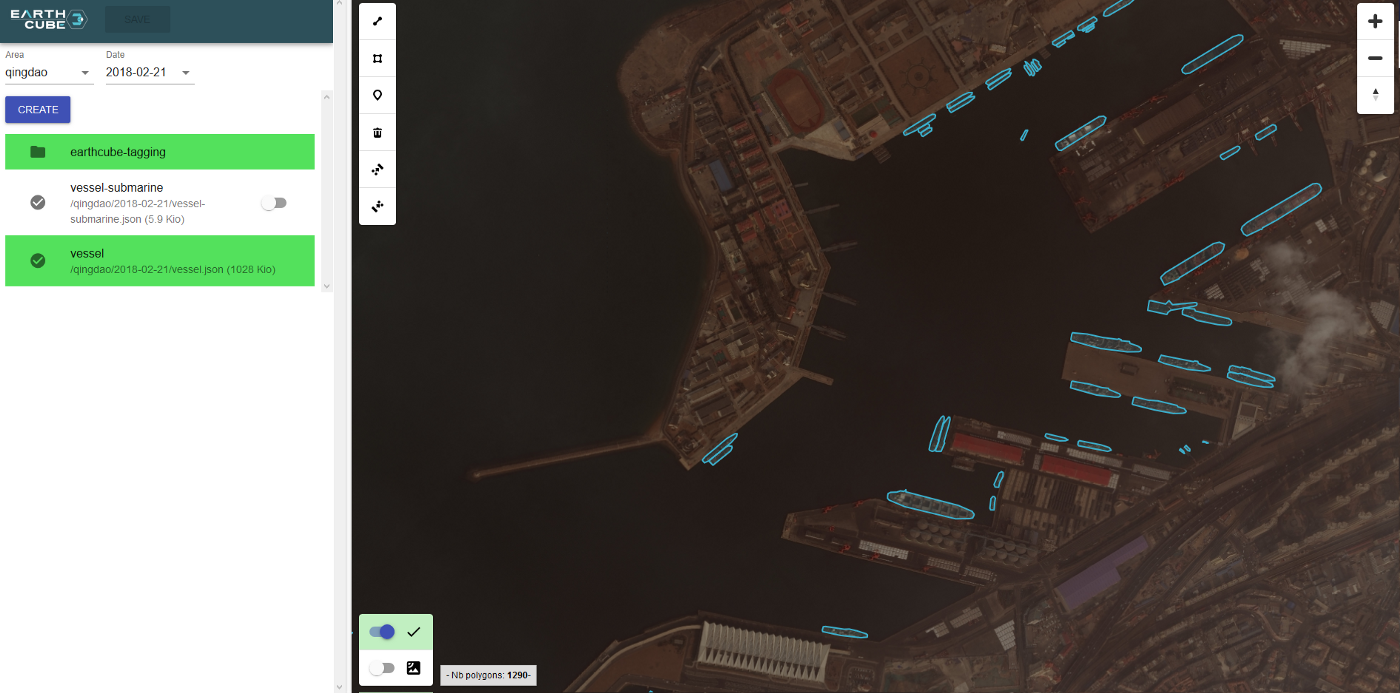
Back into the data science cycle : once images are labeled, you will need to develop new models or adapt the existing ones to your framework, prepare your options and set up your experiments. In order to do so, we built our own keras-based AI library that allows the quick deployment of new architectures with very few developments needed. Thus, we can innovate in short cycles, test new ideas and implementations, and increase our R&D efficiency.
Before training, datasets are built and made available to the data scientists via an API and Yaml interfaces. No original data is pulled on training machines, datasets are generated on servers, based on image databases and queries from the data scientists.
How does it help and why this is important?
- First, at anytime, when an image is labeled, it is directly made available to the data scientists : no files exchange is needed and all queries are standardized and tracked.
- Datasets can be built based on PostGis geographical queries, allowing to test several configurations. Then, if I want every labeled images containing cars and boats in Ukraine for instance, I can obtain it with a simple API call.
- Finally it ensures traceability: all dataset generations are logged and saved so that I can retrieve the exact parameters I used to create a given dataset, even six month after.
It all seems pretty straightforward but it is absolutely paramount when labeling millions of objects on thousands of satellite images, especially if you want to shorten your dev cycles. Without versioning and tracking, your company datasets will turn into a giant pile of unusable bloat within months.
Black magic
Once you have your dataset, you will need to use it to answer your questions and train your model. But first, you have to choose your hyperparameters.
For instance, regarding object detection, you can have three approaches for the architecture alone before even starting your development:
- Segmentation: efficient on small objects but harder to separate and could necessitate more images to train
- Object detection : efficient on large objects but can struggle to detect/separate small targets. It is also harder to train
- Instance segmentation: can combine the advantages of segmentation and object detection but it is not easy neither to implement nor train


Also, each approach can be used with several models, methodologies and hyper-parameters. We had long philosophical discussions with the team in order to find the best approach for each problem, but to be honest the truth really is ‘‘it depends’’. And this is actually true for most things in deep learning… Should I use Adam? SGD? What kind of data augmentation works better? Is a Unet preferable to a Segnet? The only definitive answer I can give is “it depends”.
For example, we chose to use segmentation for car detection as it offers much better performances. They were achieved switching between Cross-entropy and custom Jacquard loss mid training with various radiometric augmentations and a highly customized architecture. However on some other tasks, we found that nothing worked better than an off-the-shelf Unet with a “simple” binary cross-entropy launch for 300 epoch.
On the other hand, regarding boat detection, segmentation gives poor results and MaskRccn and object detection both work very well. Oddly, using hard example mining with object detection increases performances significantly but did not add much on instance segmentation. And this is just the beginning. Literature is moving so fast that there are no definitive answers. We are testing — as we speak, a modified Retinanet approach that could move some of our detection algorithms out of segmentation. This is why data scientists also need to be researchers: they need to be able to tweak parameters before and during trainings, continuously read papers, implement new architectures and generally speaking test new stuffs as often as possible.
From an outsider point of view it may seem a bit overwhelming. Some might say that the technology is not mature. But if you take a step back it is totally natural. With the hype, AI has been seen as a “black magic” solution to solve every data-related problem. It is not. AI is a set of frameworks and toolboxes one can use to automatize various complex or repetitive tasks.
What we found is that, when dealing with monitoring from Space, it is needed to automatize hundreds of different tasks using dozens of different data types. Most of the time, “off the shelf” solutions were not delivering strong enough performances, so we had to develop problem-specific architectures and training strategies. This ‘specialization’ increases with the performance requirements (the famous “no free lunch theorem!”). Detecting fighters on 30cm satellite imagery in the desert landscape will probably not use the same network as detecting bombers on 1m resolution images in Russia if you target >90% F1 score. However, to iterate fast on this customization you need a very strong framework to train, test and productize your algorithm.
My first job was at Airbus, working on Jupiter Icy Moon Explorer mission. Obviously, there was no unique definitive answer for every problem as we were trying to build a spacecraft to explore the biggest planet of the solar system. But there were processes, frameworks and tools.
Test, test and let others decide
To cope with the complexity of remote sensing AI-based product, you need to develop a toolbox including three things:
- A good dev framework to ensure the fast development of specialized deep learning solutions with complete reproducibility.
- The ability to test these architectures on large quantities and parameters to be sure to obtain suitable models in pre-production
- The ability to deploy these models in production with a business-oriented view on the test results
From research to production, you need to have the smallest cycles possible.
To do that, we pushed the framework philosophy we developed for data generation towards code design, test and iteration. When a new model is trained and seems ok for the data scientist, it is then pushed in “pre-prod” where it is tested on various datasets. Performances are automatically stored in our cloud. All training parameters, datasets and the different steps of the training are versioned so that nothing can be lost on the way.
The next part is critical. From prototype to production there is often a “gap” which very often resides in the reliability of the algorithm. And most of the time, it ends in the amount of tests performed. However, testing AI can be expensive, especially with big models and >1Gpix satellites images. You may need expensive and precious GPU to achieve a reasonable testing time. Thanks to Intel MKL DNN library, we implemented a way to leverage cheaper CPU machines within a reasonable computing timeframe, thus giving us the ability to test dozens of models in parallel painlessly.
Finally, when the best models are pre-selected, putting them in production is as simple as a click: our GIS team has a web interface with all the tests results, so they just have to select the best one for the best usage or simply relaunch some additional tests if needed. Yes you read it well. It is our GIS team which selects which model to use.
Why? Because it is the team which is actually getting the clients’ problems solved. They are the ones familiar with GeoInt issues, having looked at hundreds of satellites images. Most importantly, they studied the area we are putting the algorithm in production on. They know the sensors that are the most available on each site, what weather conditions and observables are more present, the image qualities to be expected and when and where previous algorithms performed poorly . They have the ability to interpret test results depending on test data. So they get to decide which model goes in prod on which site. Having a framework that allows non-expert people to deploy AI tools is really a game changer in term of industrialisation.
However, in the end, we always go back to the data: after pre-prod tests, if the results are not satisfying, we leverage a slightly modified version of our labelling platform to correct some masks, we put the new data back in training and improve our model rapidly through continuous learning.
We can say we make AI as a “software”.


